SHAPED BY MOTION
👁 1983 |
| 2023-02
motion feedback & reaction diffusion / DLA & material
Motion feedback generated from simple video camera input can be combined together with typical digital visual simulations like reaction diffusion based on shader technology. In this sketch, the motion data is mixed with the reaction feedback buffer, then recorded and piped into Stable Diffusion API/img2img. With a pretty simple prompt setup, a wide range of materials and interpretations of the video footage can be archieved.
On top of that, each frame of this setup can be the source of a depthmap calculation. Therefore it is possible to generate 3D shapes from this plain 2D setup potentially. As already seen in current photogrammetry setups, machine learning algorithms might help to generate proper, consisten depth information to generate relevant, timebased geometry.
latent motion detection


Using a simple motion detection compute shader occupied by a simple webcam, offers the possibility to track any motion over time. This can be done if „motion triggered“ pixels fade out slowly. The motion of the body can therefor be tracked in a straight forward, cheap way. Try the shader for yourself here: https://www.shadertoy.com/view/DlBSRm
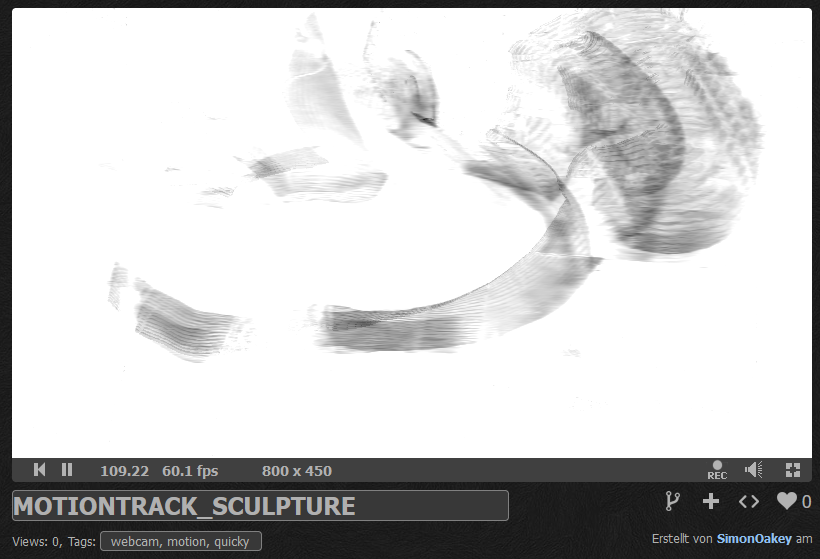
body motion to form sketches
The grainy and often noisy motion „maps“ suit well into the Stable Diffusion img2img pipeline. According to a formal prompt like: ((sculpture object made of porcelain)) with contemporary black white patterns design, glossy, realistic, dynamic shape , ((plain white background)), studio lightning – we can generate organic sculptures and object close to the motion profile, but also freely, playing with cfg and denoising strength.



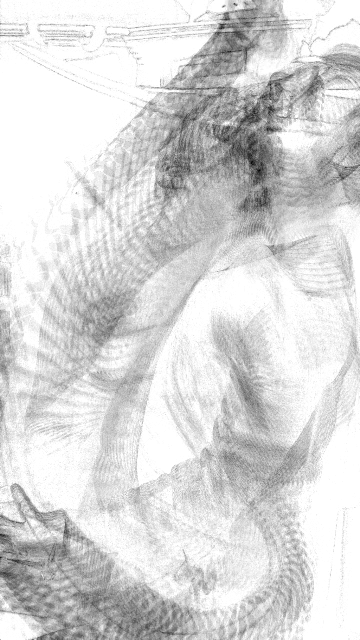

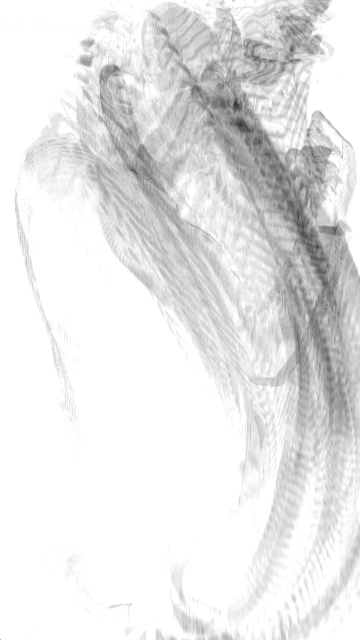

Image any material!
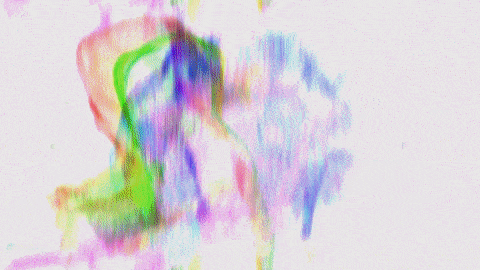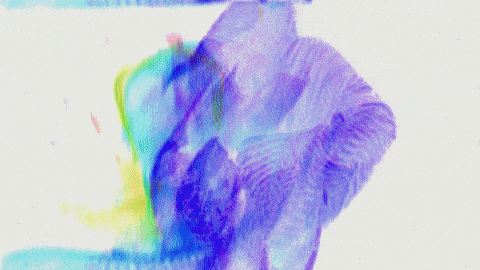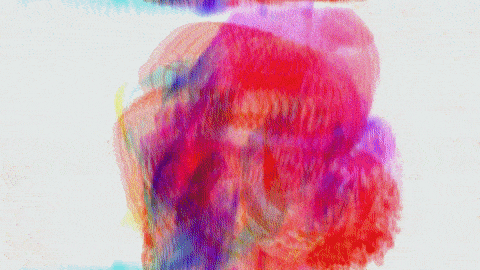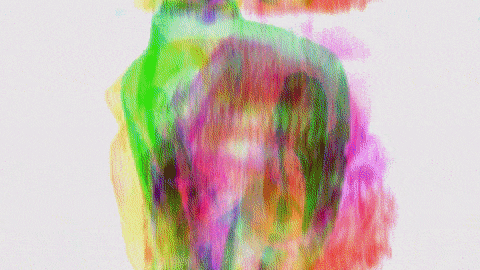
screencast of a webcam based simple motion tracker >>> PLAY ONLINE: https://www.shadertoy.com/view/DlBSRm
Using the prompt input to focus on different material properties or physical behaviour – offers infinite way to creatively postprocess the initial body motion based input. In the near future, the SD AI pipeline will run as realtime filter on top of the „basic“ input. So creating shapes with proper material visualization can be called a creative dialog?

COMPLEMENTARY PROMPT: abstract sculpture (( made from < any material description here> )), dynamic, detailed realistic photography, sharpened, in focus, male, vivid colors, studio lightning ||| CFG 9 / DENOISE ~0.4 / STEPS ~ 50

PROMPT: oil and water liquid drops

PROMPT: fluffy smoke and clouds

PROMPT: translucent organic silicone and glass

PROMPT: fluffy fur and hair flowing in dynamic direction

PROMPT: single cords and threads in no gravity
motion feedback & reaction diffusion / DLA & material
Motion feedback generated from simple video camera input can be combined together with typical digital visual simulations like reaction diffusion based on shader technology. In this sketch, the motion data is mixed with the reaction feedback buffer, then recorded and piped into Stable Diffusion API/img2img. With a pretty simple prompt setup, a wide range of materials and interpretations of the video footage can be archieved.
On top of that, each frame of this setup can be the source of a depthmap calculation. Therefore it is possible to generate 3D shapes from this plain 2D setup potentially. As already seen in current photogrammetry setups, machine learning algorithms might help to generate proper, consisten depth information to generate relevant, timebased geometry.
latent motion detection
Using a simple motion detection compute shader occupied by a simple webcam, offers the possibility to track any motion over time. This can be done if „motion triggered“ pixels fade out slowly. The motion of the body can therefor be tracked in a straight forward, cheap way. Try the shader for yourself here: https://www.shadertoy.com/view/DlBSRm
body motion to form sketches
The grainy and often noisy motion „maps“ suit well into the Stable Diffusion img2img pipeline. According to a formal prompt like: ((sculpture object made of porcelain)) with contemporary black white patterns design, glossy, realistic, dynamic shape , ((plain white background)), studio lightning – we can generate organic sculptures and object close to the motion profile, but also freely, playing with cfg and denoising strength.
Image any material!
screencast of a webcam based simple motion tracker >>> PLAY ONLINE: https://www.shadertoy.com/view/DlBSRm
Using the prompt input to focus on different material properties or physical behaviour – offers infinite way to creatively postprocess the initial body motion based input. In the near future, the SD AI pipeline will run as realtime filter on top of the „basic“ input. So creating shapes with proper material visualization can be called a creative dialog?
COMPLEMENTARY PROMPT: abstract sculpture (( made from < any material description here> )), dynamic, detailed realistic photography, sharpened, in focus, male, vivid colors, studio lightning ||| CFG 9 / DENOISE ~0.4 / STEPS ~ 50
PROMPT: oil and water liquid drops
PROMPT: fluffy smoke and clouds
PROMPT: translucent organic silicone and glass
PROMPT: fluffy fur and hair flowing in dynamic direction
PROMPT: single cords and threads in no gravity